- 과학향기 Story
- 스토리
스토리
새로운 염기서열분석 기법, 인간 유전자 지도를 완결 짓다
<KISTI의 과학향기> 제3748호 2022년 05월 09일2003년 4월 완성된 ‘인간 게놈 프로젝트(HGP)’의 인간 유전자 지도는 2000년대 초반의 생명과학 연구, 혹은 과학계 전체 연구 중에서도 탁월한 성취로 꼽힌다. 2만 500여 개에 달하는 유전자의 구조와 조직, 기능에 관한 상세 정보를 담은 인간 유전자 지도는 전 세계 20여 개 유전자 분석 기관의 협력으로 탄생했다. 프로젝트의 가능성을 논의한 초기 단계까지 포함하면 근 20년에 걸쳐 진행된 장기 프로젝트다.
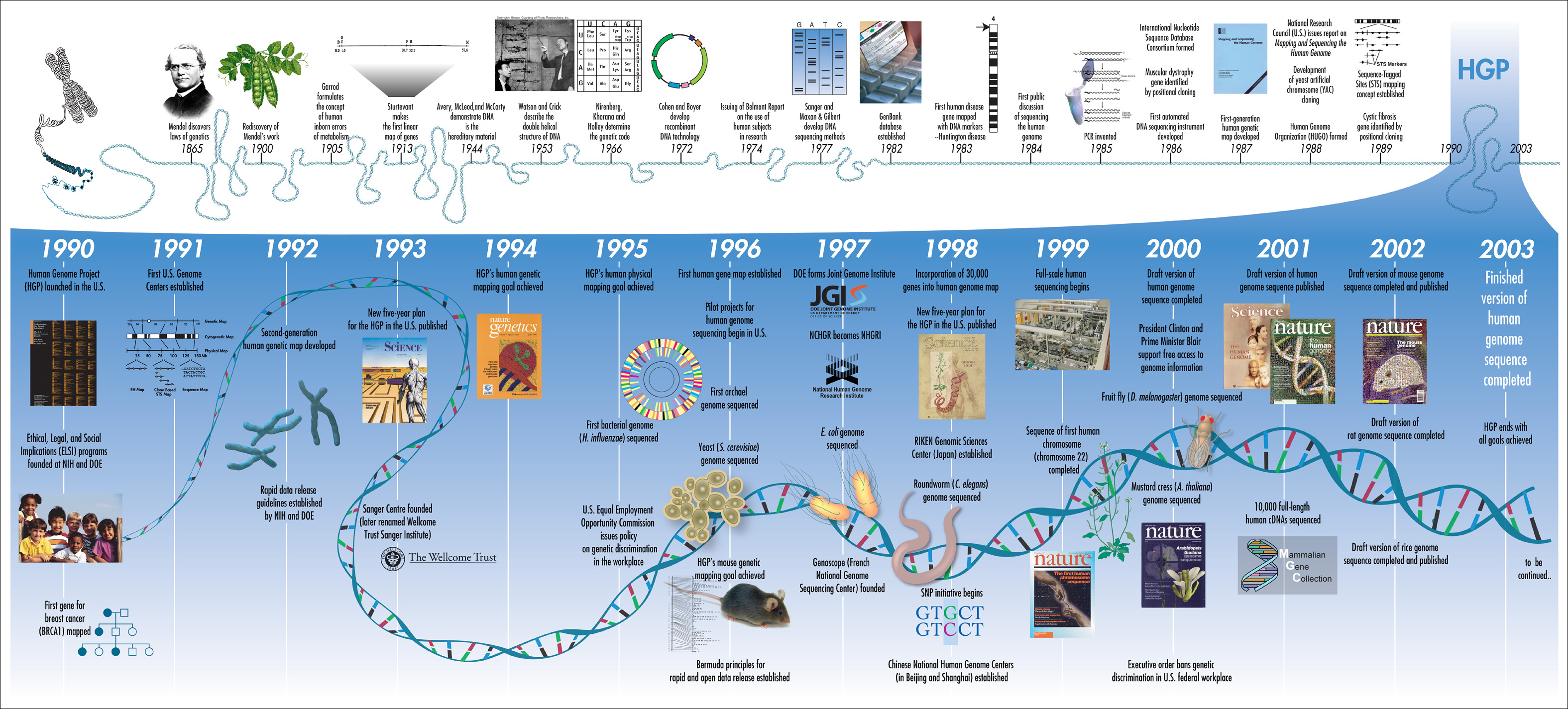
그림 1. 인간 게놈 프로젝트의 타임라인. (출처: Darryl Leja, NHGRI)
그러나 인간 게놈 프로젝트의 유명세에 비해 그 완성품에 미세한 공백이 있었다는 사실은 잘 알려져 있지 않다. 2019년까지도 인간 유전체의 8%는 해독되지 않은 채 남겨져 있었다. 그리고 2022년 3월 31일, 국제 학술지 《사이언스》에 30억 개 염기쌍 전체의 서열 정보를 채운 유전자 지도가 발표됐다. 이는 ‘텔로미어 투 텔로미어(T2T)’라는 이름의 국제 컨소시엄에 참여한 114명의 과학자, ‘롱 리드(Long-read)’라는 새로운 시퀀싱 기법 덕분에 가능한 일이었다.
인간 유전자 지도를 향한 여정
인간 유전자 지도 제작의 꿈은 1980년대 중반의 일로 거슬러 올라간다. 1984년 겨울, 미국 유타 주에 위치한 도시 알타에서 인간 신체에 영향을 주는 돌연변이 유전자를 탐지하기 위한 방책을 논하는 회담이 열렸다. 미국 에너지부(DOE)와, 환경적 변종과 발암 물질 대응을 위한 국제 위원회(ICPEMC)의 지원으로 열린 이 회담의 참석자들은, 돌연변이 예측을 위해서는 ‘엄청나게 크고 복잡하고 막대한 예산이 드는’ 연구 프로젝트가 필요하다고 했다. DOE와 미국 국립 보건원(NIH)는 과학자, 행정가, 과학 정책 전문가의 자문과 타당성 검토를 거쳐 15년의 연한을 둔 프로젝트 초기 계획을 발표했고, 이 프로젝트는 2800명 이상의 연구원이 참여한 국제 컨소시엄으로 발전해 나갔다.

그림 2. 당시 프랜시스 콜린스 미국국립보건원(NIH) 원장이 인간 게놈 프로젝트의 성공을 발표하고 있다. (출처: Ernie Branson, NIH)
2000년 6월, 국제 컨소시엄은 인간 유전체 30억 개 염기쌍 서열 중 약 90%가 완성된 첫 번째 초안을 발표했다. 이후의 과정은 초기 염기 서열을 ‘완성된’ 염기 서열로 변환하는 과정이었다. 완성된 염기 서열이란 1만 자당 한 개 미만의 오류를 보일 정도로 정확도가 높고, 서열 정보가 연속적인 것을 의미한다. 유전 형질을 발현하는 기능적 단위인 유전자를 기준으로 하면 2003년에 발표된 지도는 인간 유전자가 포함된 영역의 99%를 99.99%의 정확도로 분석해 냈다는 점에서 완성도가 높았으나 유전체 전체로 보면 듬성듬성 공백이 있었다. 반복 구간이 많은 중심체나 리보솜 DNA 등 전체의 15%가량은 당시의 기술적 한계로 확인할 수 없었고, 특히 덩어리가 큰 구간은 3년 전까지도 해독되지 않은 상태였다.
미지의 영역으로 나아간 과학자들
T2T 컨소시엄에 참여한 미국 국립인간유전체연구소(NHGRI)의 연구원 에반 아이클러는 정보 값이 없으리라 무시된 미완의 영역에 주목했다. 1990년의 인간 게놈 프로젝트에도 참여한 경력이 있는 그는 기이하게 긴 반복 구간, 여분의 유전자 사본이 인간의 진화와 질병 이해에 중요한 역할을 하리라는 믿음을 줄곧 유지했다. 지난 3월 발표된 유전체 지도는 한 번에 수만 개 이상의 염기쌍 서열을 읽는 롱 리드 기술을 적용해 이전의 기술적 한계를 극복할 수 있었다.
생명 공학 기업 퍼시픽 바이오 사이언스(Pac Bio), 옥스퍼드 나노포어 테크놀로지(ONT)가 개발한 롱 리드 시퀀싱 기술은 염기 서열을 한 번에 만 개 이상, 많게는 백만 개 이상 읽어내는 최신 시퀀싱 기술이다. 에반 아이클러를 사사한 캘리포니아 주립대 산타크루즈 캠퍼스(UCSC)의 카렌 미가, NHGRI의 애덤 필리피 등의 연구원은 이 기술이 지도의 공백을 메울 해결책이 되리라는 것을 감지하고 있었다.
컨소시엄의 연구원들은 두 기업의 기술을 혼합하는 방법을 택했다. 한 번에 많은 염기 서열을 읽을 수 있는 팩 바이오의 기술과, 판독 길이는 짧지만 정확도가 높은 ONT의 데이터를 조합한 것이다. 이렇게 새로 해독된 2억 개의 염기쌍에는 단백질을 만드는 유전자 2000여 개, 유전 질환과 관련된 변이 622개를 포함한 DNA 변이 200만 개가 포함되어 있었다. 이러한 성과는 인간의 세포 분열 방식에 대한 새로운 이해와 유전체 변이로 인해 발생하는 다운증후군 등의 질환, 난임 등을 규명할 단서를 제공한다.
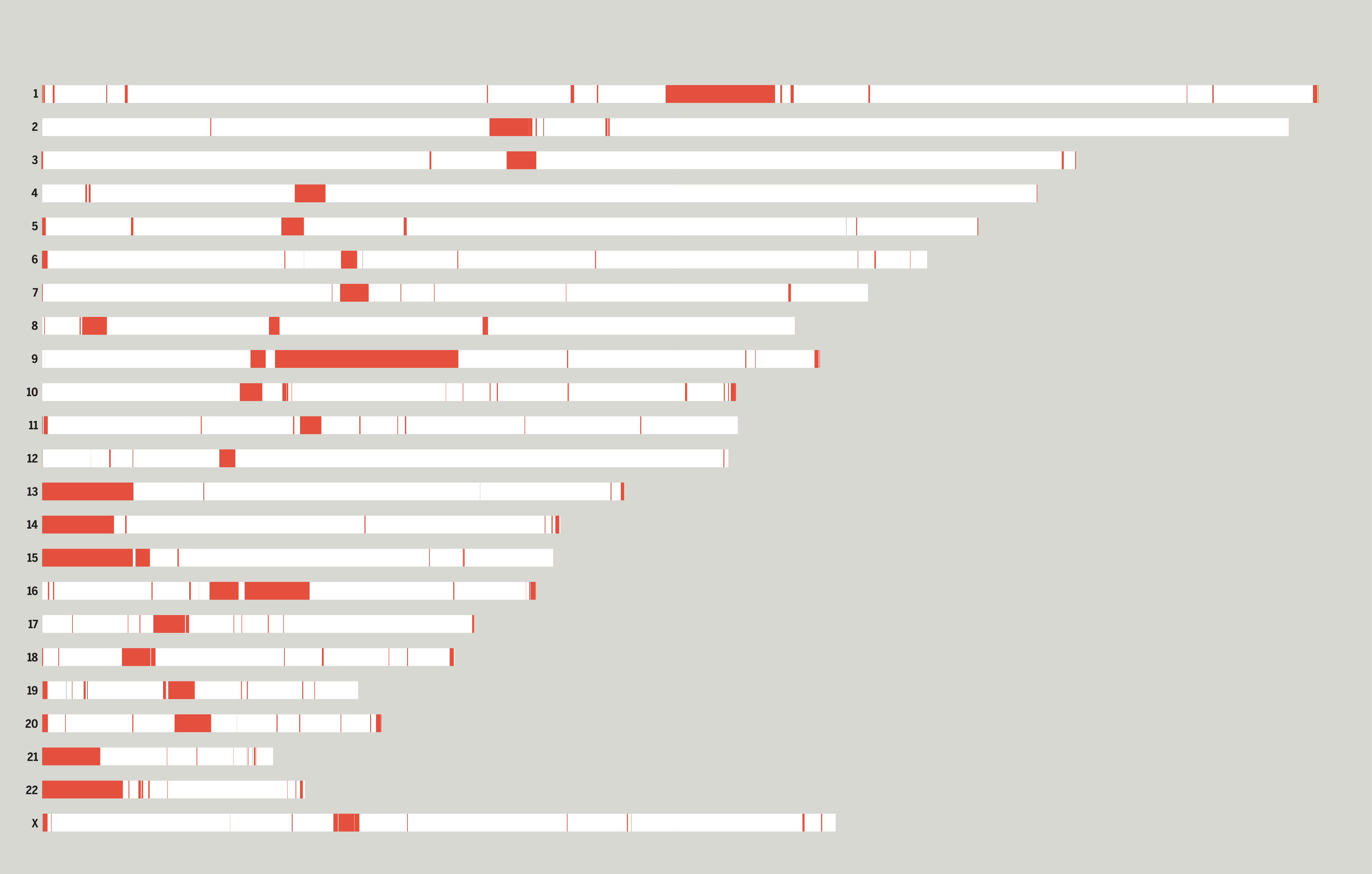
단 하나의 인간 유전자 지도를 완성하려는 여정은 이것으로 끝일까? 기술의 혁신이 정크 DNA로 취급된 영역을 해독할 길을 열어 주었다면, 염기 서열의 모든 자리를 밝힌 지도는 정확도의 측면에서 그 영역을 넓히고 있다. 이번 인간 유전자 지도에 활용된 유전체는 유럽 남성의 것이다. T2T의 연구진은 향후 인종 등 유전체 다양성을 확보하고자 사람 수로 따지면 350명 분량에 달하는 인간 유전체를 추가 분석하기로 했다. 지난 세기의 과학이 그렸던 단 하나의 청사진은 현재를 살아가는 인류의 수수께끼를 향해 그 깊이를 더하고 있다.
*참고 자료
- Science, Vol.376(2022.04), https://www.science.org/toc/science/376/6588
- NIH 국립 인간 유전체 연구소, https://www.genome.gov/human-genome-project
Meghan Rosen, “Complete human genome deciphered for the first time,”
- EurekAlert, https://www.eurekalert.org/news-releases/946948
- 조승한, 「인간 유전체 풀리지 않던 ‘8% 빈칸’ 모두 채웠다」, 동아사이언스, 2022년 4월 4일, https://www.dongascience.com/news.php?idx=53379
- 임지선, 「롱 리드를 이용한 인간 유전체 시퀀싱과 그 적용」, BRIC, https://www.ibric.org/myboard/read.php?Board=report&id=3637; Glennis A. Logsdon, Mitchell R. Vollger & Evan E. Eichler(2020), “Long-read human genome sequencing and its applications,“ Nature Reviews Genetics Vol.21: pp.597~614.
글: 맹미선 과학칼럼니스트/ 일러스트: 유진성 작가
추천 콘텐츠
인기 스토리
-
- 저주파 자극기, 계속 써도 괜찮을까?
- 최근 목이나 어깨, 허리 등에 부착해 사용하는 저주파 자극기가 인기다. 물리치료실이 아니라 가정에서 손쉽게 쓸 수 있도록 작고 가벼울 뿐만 아니라 배터리 충전으로 반나절 넘게 작동한다. 게다가 가격도 저렴하다. SNS를 타고 효과가 좋다는 입소문을 퍼지면서 판매량도 늘고 있다. 저주파 자극기는 전기근육자극(Electrical Muscle Stimu...
-
- 우리 얼굴에 벌레가 산다? 모낭충의 비밀스러운 삶
- 썩 유쾌한 얘기는 아니지만, 우리 피부에는 세균 같은 각종 미생물 외에도 작은 진드기가 살고 있다. 바로 모낭충이다. 모낭충은 인간의 피부에 살면서 번식하고, 세대를 이어 간다. 태어난 지 며칠 되지 않은 신생아를 제외한 거의 모든 사람의 피부에 모낭충이 산다. 인간의 피부에 사는 모낭충은 크게 두 종류가 있다. 하나는 주로 얼굴의 모낭에 사는...
-
- [과학향기 Story] 차 한 잔에 중금속이 줄었다? 찻잎의 숨겨진 능력!
- 하루하루 바쁘게 사는 현대인들은 잠을 깨우기 위해 커피를 마신다. 이에 커피 소비량이 급격히 늘어나고 있지만, 아직 커피의 소비량은 ‘차(茶)’의 소비량을 뛰어넘지 못했다. 이는 많은 국가에서 차를 일상적으로 소비하는 문화가 자리 잡고 있기 때문이다. 또한 카페인 외에도 다양한 성분이 함유돼 있어, 건강을 목적으로 섭취하는 사람들도 다수 존재한다. ...
이 주제의 다른 글
- [과학향기 Story] '디저트 배'는 진짜였다! 당신 뇌 속의 달콤한 속삭임
- [과학향기 for Kids] 나무 뗏목 타고 8000km 항해? 태평양을 건넌 이구아나의 대모험
- [과학향기 for kids] 추위에도 끄떡없어! 북극곰의 털이 얼어붙지 않는 비결은?
- [과학향기 for kids] 사람 근육으로 움직이는 로봇 손 등장!
- [과학향기 Story] 죽음을 초월한 인간, 《미키17》이 던지는 질문
- [과학향기 Story] 인간의 뇌, 와이파이보다 느리다니?
- [과학향기 for Kids] 귓바퀴의 조상은 물고기의 아가미?
- [과학향기 Story] 하루 한 두 잔은 괜찮다더니… 알코올, 암 위험 높이고 건강 이점 없어
- [과학향기 for Kids] 잘 모를 때 친구 따라 하는 이유!
- [과학향기 for Kids] 한 달 동안 똥을 참는 올챙이가 있다?


좋은 말씀 감사합니다. 단, 식상한 부분은 여전히 있습니다.
2022-05-09
답글 0